作者:哆啦356 | 来源:互联网 | 2023-09-06 12:32
篇首语:本文由编程笔记#小编为大家整理,主要介绍了中文起,Python 字体反爬实战案例,再一点相关的知识,希望对你有一定的参考价值。
⛳️ 起点 实战场景
本次采集的案例是点起文中,你可以随机打开一本目标xiaoshuo,检查一下网络请求中是否存在字体文件响应数据。
Python脱敏处理.Python脱敏处理.Python脱敏处理/info/2952453/#Catalog
字体加密位置呈现的效果如下图所示。
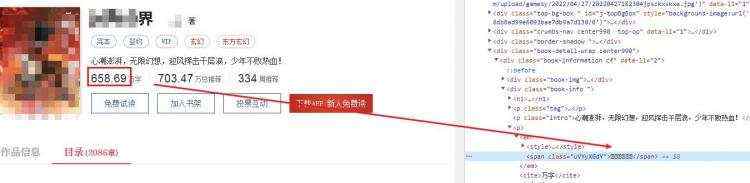
编写网页爬取代码,查看其字体位置使用的编码。
import requests
headers =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
"Origin": https://Python脱敏处理.com,
"referer": "https://Python脱敏处理.com"
respOnse= requests.get(url=https://Python脱敏处理/info/2952453/,headers=headers)
response.encoding = utf-8
print(response.text[:20000])
截取源码部分,查看编码内容。
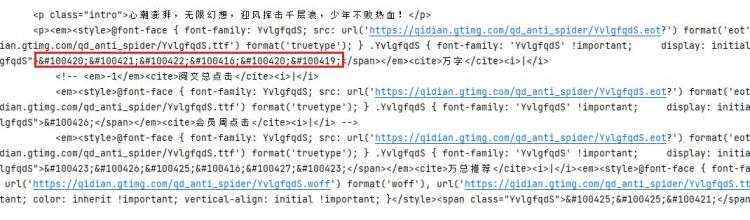
同时下载本页面的字体文件,用工具打开之后,发现字体编码图形顺序没有什么变化,这对于后续我们解决反爬就变得非常简单了。

接下来读取和解构一下这个字体文件,在其中找到能用的数据。
from fontTools.ttLib import TTFont
import io
file_woff = ./fonts/YOfzYtjr.woff
with open(file_woff, rb) as font_file:
fOnt= TTFont(io.BytesIO(font_file.read())) # 转换成字体对象
#字体映射关系
font_cmap = font[cmap].getBestCmap()
print(font_cmap)
输出的信息为:
100418: two, 100420: seven, 100421: five, 100422: nine, 100423: six, 100424: three, 100425: four, 100426: zero, 100427: one, 100428: period, 100429: eight
接下来在回头去看一下刚才字体反爬位置的特殊字符与字体编码。
网页特殊字符
𘞱𘞯𘞴𘞲𘞱𘞭
字体编码
100269: nine, 100271: five, 100272: three, 100273: six, 100274: period, 100275: one, 100276: eight, 100277: two, 100278: four, 100279: seven, 100280: zero
得到最终的结果。
&#100273 -> 6










 京公网安备 11010802041100号
京公网安备 11010802041100号